- 에이전트를 만들 때 시간이 오래 걸리는 건 에이전트 로직이 아니라 도구 설계와 LLM 인프라다
- “좋은 에이전트”의 기준이 학계, SNS, 회사에서 전부 달라서 이 병목이 잘 안 보인다
- Open API Specification에서 tool 변환, Port and Adapter, LLM-as-Judge 등으로 접근할 수 있다
에이전트를 만들다 보면 정작 시간이 오래 걸리는 건 에이전트 로직이 아니다. 도구를 어떻게 정의하고 연결할 것인가, LLM 인프라를 어떻게 추상화할 것인가, 이걸 어떻게 평가할 것인가. LangCon 2025에서 이 문제들을 “Rethinking about Agent and Tools”라는 제목으로 정리했다.
세 관점
에이전트의 정의 자체는 단순하다. 계획을 가지고 목표 도달 여부를 검증할 수 있는 application. 도구는 에이전트가 활용 가능한 function. 그런데 “좋은”이 붙는 순간 관점이 갈린다.
학계에서는 Huang et al.의 “Language Models as Zero-Shot Planners” (2022)나 Lu et al.의 OctoTools (2025)처럼 새로운 해결 영역이나 통합 프레임워크가 기준이다. SNS에서는 AutoGPT(2023)처럼 매력적인 PoC가 기준이고, 회사에서는 Perplexity처럼 투입 예산 대비 효용성이 기준이다.
관점이 이렇게 다른데도 공통점이 하나 있다. 어디서 에이전트를 만들든, 실제 병목은 에이전트 자체가 아니라 그 주변의 기술적 인프라에서 생긴다는 것이다.
도구가 병목
가장 흔한 경우가 Open API Specification으로 정의된 RESTful API를 LLM function calling 스키마로 변환하는 것이다. 단순히 spec 문서를 programmable type과 function calling schema로 바꾸는 건데, 기존 오픈소스 generator들이 use case에 잘 맞지 않아서 사람의 손코딩이 필요한 경우가 많았다. OpenAI 기준으로는 functions schema generator를 직접 구현해야 하고, OpenAI Python SDK의 스키마를 참조하면 확인이 가능하다. composio.dev처럼 Python script에서 function calling spec으로 변환해주는 서비스도 있는데, 이런 서비스가 존재한다는 것 자체가 이 과정의 번거로움을 보여주는 것 같다.
웹 검색도 비슷하다. 가장 널리 사용되는 tool use case인데, 웹 크롤링, 페이지 클렌징, 요약 등의 인프라 작업이 수반된다. AI 엔지니어보다 데이터 엔지니어의 손이 더 필요한 영역이다. 엔터프라이즈에서는 사내 웹 검색 파이프라인을 직접 구축해야 하는 경우가 많고, 개인 프로젝트에서는 Tavily나 Firecrawl이 현실적이다. Gemini에서는 Google Search를 native하게 지원하는데, 무료 1,500 RPD 이후 1,000건당 $35다.
도구를 단순한 function이 아니라 에이전트의 핵심 기능으로 활용하는 접근도 있다. 개인화를 KnowledgeTriple(subject, predicate, object) 형태의 메모리로 구현하면, LLM이 매 iteration마다 개인화 소재를 생성하고 vector store에 저장할 수 있다. 도구 설계가 에이전트의 능력 자체를 결정하는 셈이다.
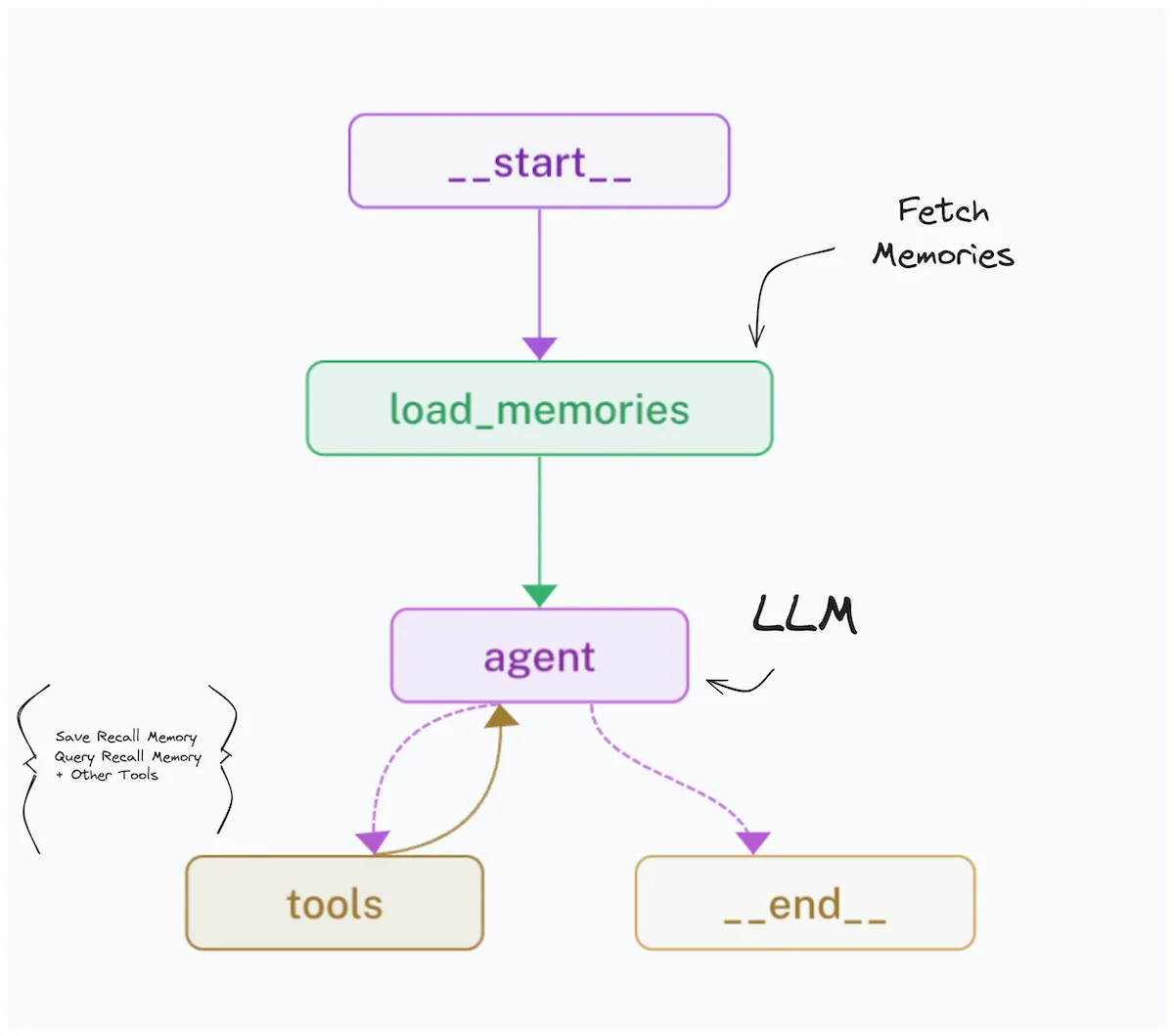
구현
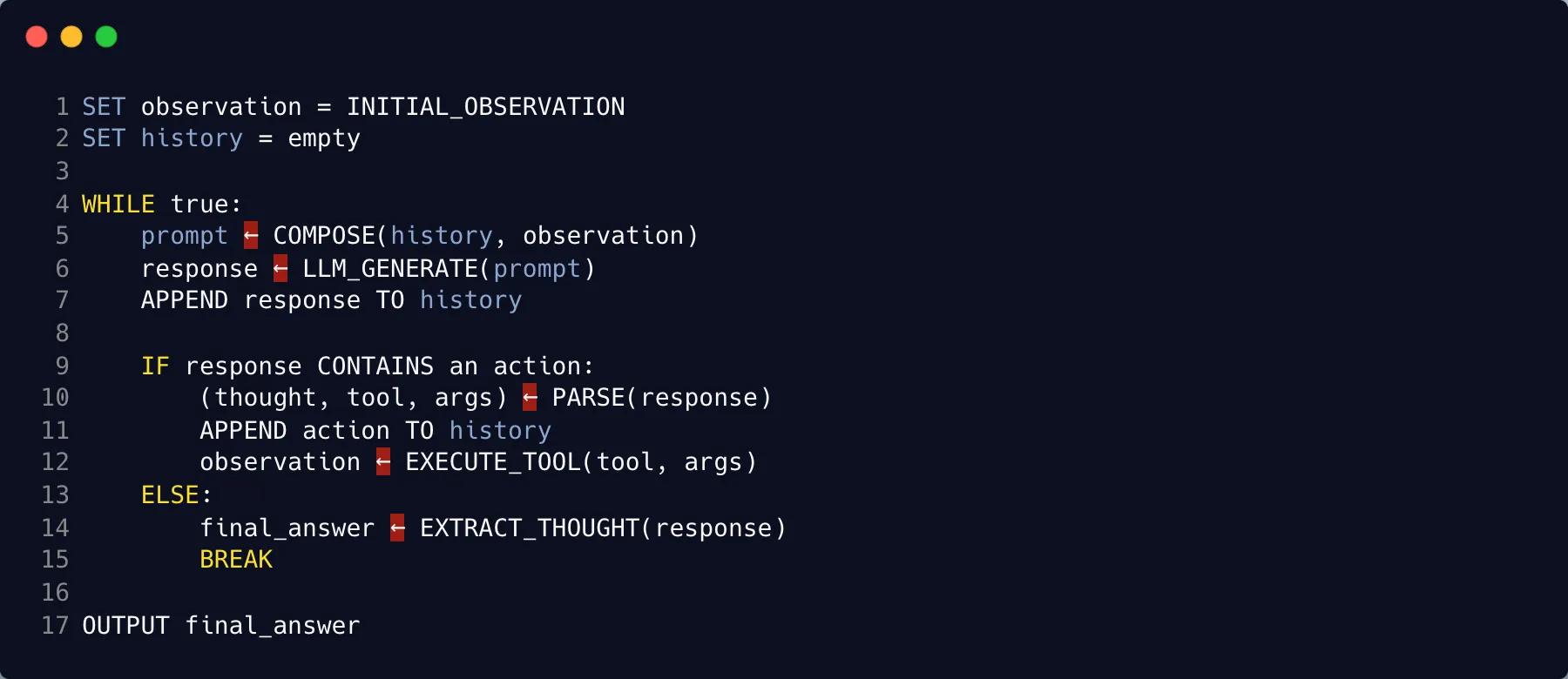
도구 문제가 해결되면 에이전트 구현 자체는 상대적으로 단순해진다. Python 기준으로 zero-base 구현이 가장 편리하고 빨랐다. 오픈소스 중에서는 FastAPI, OpenAI Python SDK, LiteLLM Proxy 정도만 사용했다. LLM 인프라 레이어를 OpenAI spec으로 통일하면 나머지가 깔끔해진다. 많은 backend-focused ML 엔지니어들이 체감하고 각자만의 솔루션을 가지고 있는 주제인데, 회사마다 이런 기반을 갖추는 속도가 다르다.
사내 자체 모델이 vLLM OpenAI Compatible Server로 서빙되고 있는 상황에서 ReAct 에이전트를 만드는 경우를 보면, LangChain으로 만들면 빠른 프로토타이핑이 가능하고 코드 압축 효과가 좋다. 하지만 agent behavior spec이 고정되고, 디버깅이나 타입 정의가 어려우며, 라이브러리 내부 로직 변경이 쉽지 않다. 자체 구현은 초기 부담이 있고 보일러 플레이트가 늘어나지만, 요구사항 반영이 용이하고 LLM provider별 기능 활용이 자유롭다. Structured Output을 반환 받고 싶을 때가 대표적인 예다.
간단한 pseudo code에서 출발해서 o3-mini로 134줄의 Python ReAct 에이전트를 만들어봤다. 코드는 gist에 올려뒀다.
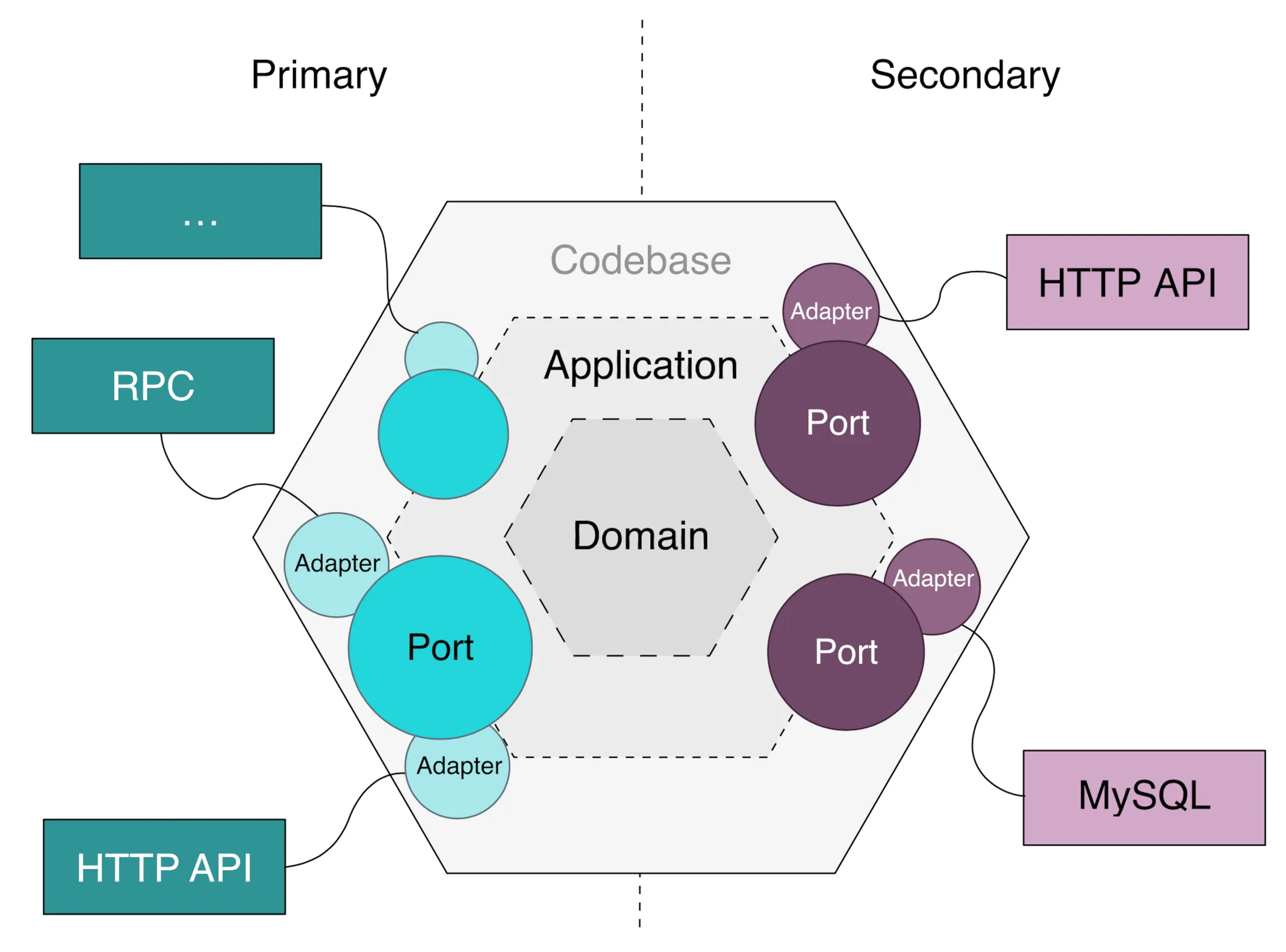
LLM을 에이전트 내에서 어떻게 사용할 것인가는 Port and Adapter 패턴이 깔끔한 해결책이라고 생각한다. LLMProviderService라는 추상 인터페이스를 정의하고, OpenAI나 LoraX 등 provider별 adapter를 구현하면, application 코드에서 LLM provider 교체가 투명해진다. vLLM OpenAI Compatible Server나 LiteLLM Proxy Server와 조합하면 된다.
평가
대화 시스템에서의 에이전트 평가는 LLM-as-Judge가 현실적이다. MT-Bench의 pairwise comparison, answer grading, reference-guided grading이나, WildBench처럼 무작위 대화 로그로부터도 평가가 가능하다. 1회 평가당 예산을 조절해서 현실적인 평가 주기와 크기를 탐색하는 게 핵심인데, 1회당 $5 정도를 기준으로 시작해볼 수 있다.
저비용 고품질을 달성하려면 end-to-end 평가와 모듈별 평가를 병행해서 가성비 영역을 정의해야 한다. 어느 모듈에서 어떤 모델을 쓸 것인지, 파라미터 대비 성능에서 sweet spot이 어디인지를 찾는 과정이다.
이건 나의 정리 방식이고, 각자의 현장에서는 또 다른 난관들이 있을 것이다.
References
- Huang, W., Abbeel, P., Pathak, D., & Mordatch, I. (2022). Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents. ICML 2022.
- Lu, P., Chen, B., Liu, S., Thapa, R., Boen, J., & Zou, J. (2025). OctoTools: An Agentic Framework with Extensible Tools for Complex Reasoning. arXiv:2502.11271.
- Zheng, L., Chiang, W., Sheng, Y., et al. (2023). Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. NeurIPS 2023.
- Lin, B.Y., Deng, Y., Chandu, K., et al. (2024). WildBench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild. arXiv:2406.04770.
- LINE Engineering. Port and Adapter Architecture.