- Quando si costruiscono agenti, il lavoro pesante non è il loop dell’agente ma la progettazione dei tool e l’infrastruttura LLM
- Il concetto di “buon agente” cambia tra accademia, social media e produzione, e questo rende il collo di bottiglia meno visibile
- Conversione da Open API Specification a tool, pattern Port and Adapter, valutazione con LLM-as-Judge sono modi per affrontarlo
Costruendo agenti, mi ritrovo sempre a spendere il tempo sulle stesse cose. Non sul loop dell’agente, ma su tutto il resto: come definire e collegare i tool, come astrarre il layer LLM, come valutare il risultato. Ho organizzato queste riflessioni in un intervento a LangCon 2025, “Rethinking about Agent and Tools”.
Tre prospettive
La definizione di agente è semplice. Un’applicazione con un piano che può verificare se ha raggiunto il suo obiettivo. Un tool è una funzione che l’agente può chiamare. Ma nel momento in cui si aggiunge “buono”, le prospettive divergono.
In accademia, il metro è la novità: “Language Models as Zero-Shot Planners” di Huang et al. (2022) ha dimostrato che GPT-3 e Sentence-BERT potevano gestire il planning; OctoTools di Lu et al. (2025) ha proposto un framework unificato su 16 benchmark. Sui social media, contano i PoC attraenti come AutoGPT (2023). In produzione, è il ROI: Perplexity che prende idee dalla comunità open-source e le trasforma in un servizio.
Criteri diversi, ma un punto in comune: ovunque si costruiscano agenti, il collo di bottiglia tende a essere fuori dall’agente stesso.
I tool sono il collo di bottiglia
Il caso più comune è convertire RESTful API definite con Open API Specification in schemi di function calling per LLM. Sembra una semplice traduzione spec-to-code, ma i generator open-source esistenti raramente si adattano al caso specifico, e si finisce per scrivere codice a mano. Con lo spec OpenAI, bisogna costruire un functions schema generator, consultando l’OpenAI Python SDK per la struttura dello schema. Servizi come composio.dev gestiscono questa traduzione da script Python a spec di function calling. L’esistenza stessa di questi servizi dice qualcosa sulla tediosità del processo.
La web search è simile. È il tool use case più diffuso, ma il lavoro infrastrutturale è più pesante del previsto: crawling, pulizia delle pagine, riassunti. Richiede più mani di data engineering che di AI engineering. In contesti enterprise, spesso bisogna costruire la pipeline di ricerca interna da zero. Per progetti personali, Tavily o Firecrawl sono più realistici. Gemini supporta nativamente Google Search come tool, con 1.500 richieste gratuite al giorno e $35 per 1.000 successive.
C’è anche l’approccio di usare i tool non come semplici funzioni ma come feature core dell’agente. Se si implementa la personalizzazione come memoria a KnowledgeTriple (subject, predicate, object), l’LLM può generare e salvare materiale di personalizzazione in un vector store a ogni iterazione. La progettazione dei tool finisce per determinare le capacità dell’agente.
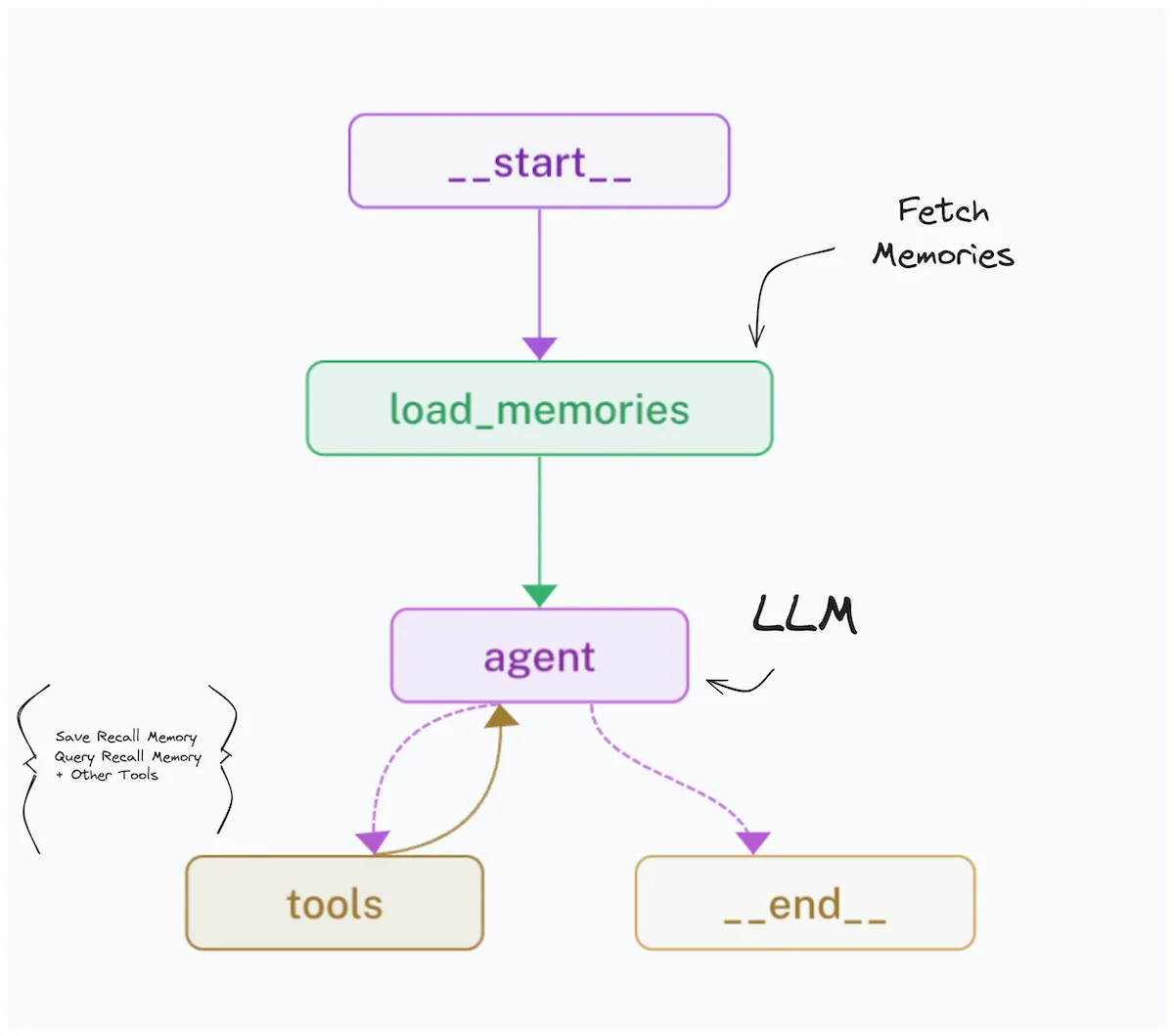
Implementazione
Risolto il problema dei tool, l’implementazione dell’agente è relativamente diretta. In Python, partire da zero è stato il percorso più veloce. Ho usato solo FastAPI, OpenAI Python SDK e LiteLLM Proxy. Unificare il layer LLM sullo spec OpenAI semplifica tutto il resto. Molti ML engineer orientati al backend hanno le proprie soluzioni, e la velocità con cui ogni azienda ci arriva varia.
Prendiamo il caso di un modello aziendale servito con vLLM OpenAI Compatible Server: costruire un agente ReAct con LangChain offre prototyping rapido e buona compressione del codice, ma il behavior spec dell’agente resta fisso, il debugging è più difficile e modificare gli internals della libreria è doloroso. L’implementazione propria ha più costo iniziale e boilerplate, ma si adatta ai requisiti più facilmente e permette di usare funzionalità specifiche di ogni provider. Structured Output è un esempio tipico.
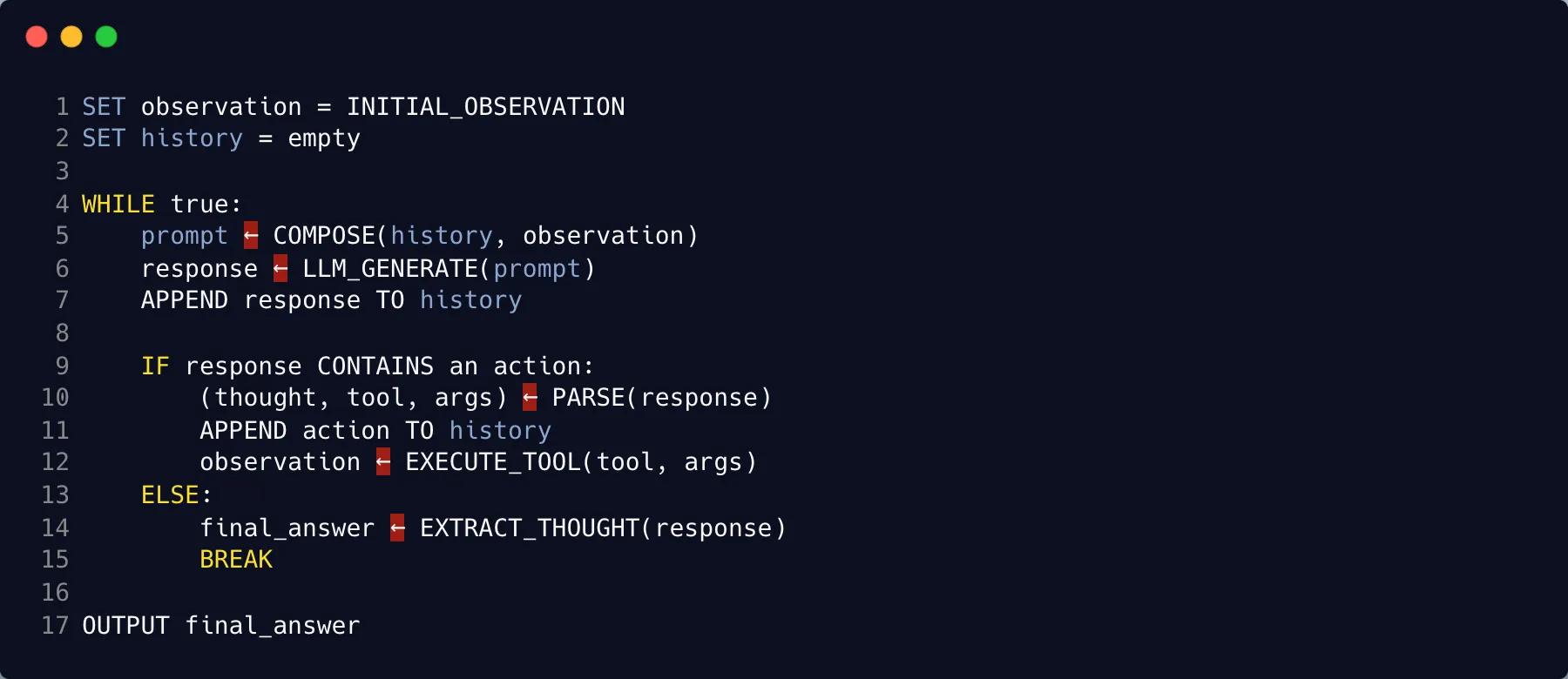
Sono partito da un semplice pseudo code e con o3-mini ho prodotto un agente ReAct in 134 righe di Python. Il codice è su gist.
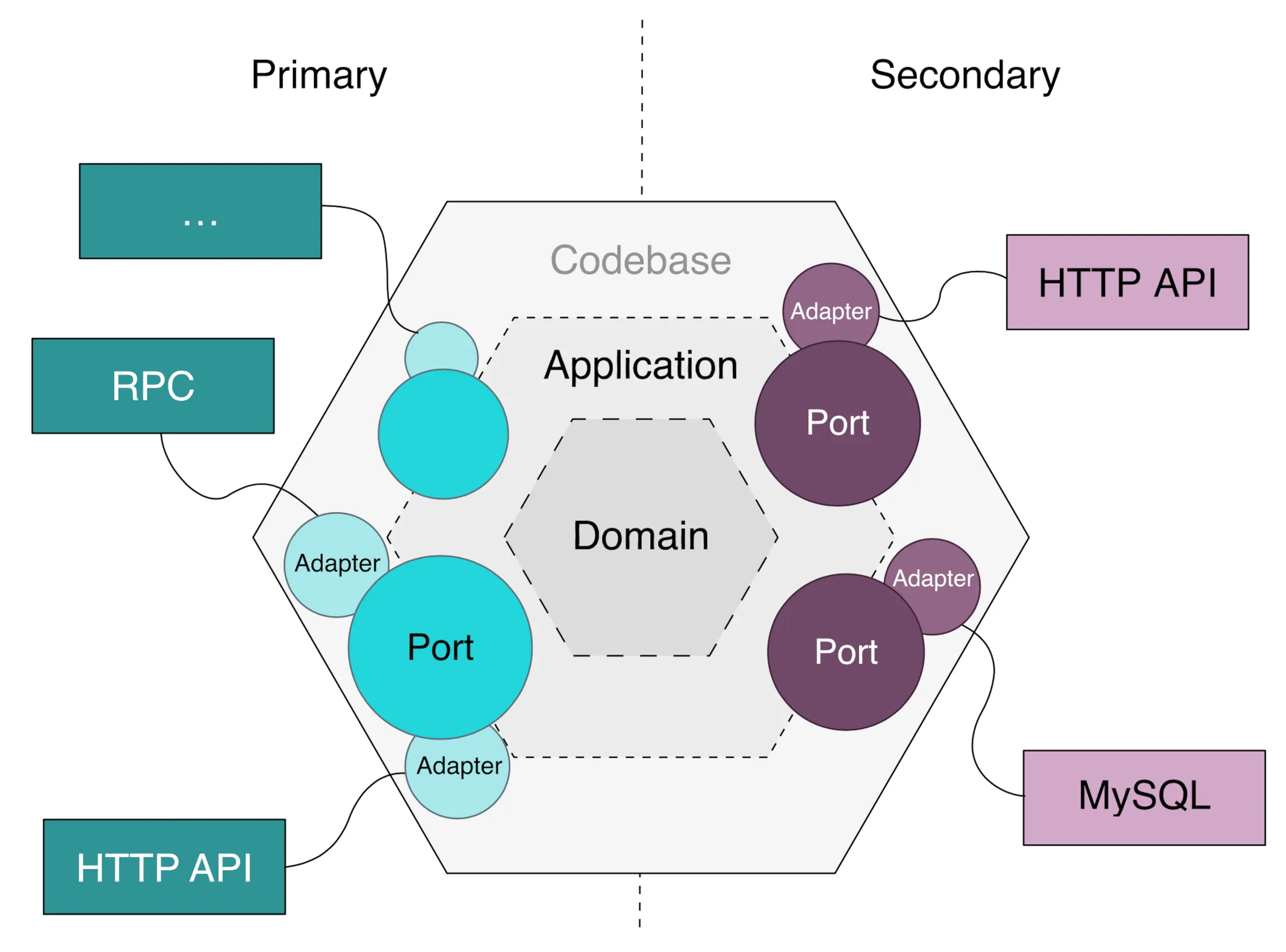
Per usare gli LLM dentro l’agente, il pattern Port and Adapter è una soluzione pulita. Si definisce un’interfaccia astratta LLMProviderService, si implementano adapter per ogni provider (OpenAI, LoraX, etc.), e lo scambio di provider diventa trasparente per il codice applicativo. Combinato con vLLM OpenAI Compatible Server o LiteLLM Proxy, si è a posto.
Valutazione
Per la valutazione degli agenti in sistemi conversazionali, LLM-as-Judge è l’approccio pratico. Il pairwise comparison di MT-Bench, l’answer grading e il reference-guided grading sono buoni riferimenti, e WildBench mostra che la valutazione da log di conversazione casuali è fattibile. Il punto chiave è calibrare il budget per valutazione per trovare cadenza e scala realistiche. Partire da circa $5 per round è un baseline ragionevole.
Raggiungere basso costo e alta qualità significa eseguire sia valutazioni end-to-end che per modulo per trovare lo sweet spot. Quale modello va in quale modulo, dove il rapporto parametri-prestazioni funziona meglio.
Questo è il mio modo di organizzare il problema. Altri avranno il proprio framework.
References
- Huang, W., Abbeel, P., Pathak, D., & Mordatch, I. (2022). Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents. ICML 2022.
- Lu, P., Chen, B., Liu, S., Thapa, R., Boen, J., & Zou, J. (2025). OctoTools: An Agentic Framework with Extensible Tools for Complex Reasoning. arXiv:2502.11271.
- Zheng, L., Chiang, W., Sheng, Y., et al. (2023). Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. NeurIPS 2023.
- Lin, B.Y., Deng, Y., Chandu, K., et al. (2024). WildBench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild. arXiv:2406.04770.
- LINE Engineering. Port and Adapter Architecture.