- When building agents, what takes time is not the agent loop but tool design and LLM infrastructure
- “Good agent” means different things in academia, on social media, and in production, which makes this bottleneck hard to see
- Open API Specification to tool conversion, Port and Adapter, and LLM-as-Judge are ways to approach it
I keep running into the same set of problems when building agents. Not the agent loop itself, but everything around it: how to wire up tools, how to abstract the LLM layer, how to evaluate any of it. I organized these into a talk called “Rethinking about Agent and Tools” at LangCon 2025.
Three takes on “good”
An agent is an application with a plan that can verify whether it reached its goal. A tool is a function the agent can call. Loose definitions, but once you add “good,” things diverge.
In academia, the bar is novelty: Huang et al.’s “Language Models as Zero-Shot Planners” (2022) showed planning was possible with GPT-3 and Sentence-BERT; Lu et al.’s OctoTools (2025) proposed a unified framework across 16 benchmarks. On social media, compelling PoCs like AutoGPT (2023) set the standard. In production, it’s ROI: Perplexity taking open-source search-agent ideas and turning them into a business.
Different criteria, but one pattern holds across all three: wherever you build agents, the bottleneck tends to be outside the agent itself.
Tools are the bottleneck
The most common case: converting RESTful APIs defined with Open API Specification into LLM function calling schemas. Sounds like a straightforward spec-to-code translation. It isn’t. Existing open-source generators rarely fit your use case, and you end up writing code by hand. On the OpenAI spec, you need to build a functions schema generator yourself (the OpenAI Python SDK is a useful reference for schema structure). Services like composio.dev handle this translation from Python scripts to function calling specs. That these services exist probably says something about how tedious the process is.
Web search is a similar story. Most widely used tool use case, but the infrastructure is heavier than you’d expect: crawling, page cleansing, summarization. Data engineering work more than AI engineering work. Enterprise means building the search pipeline in-house. For personal projects, Tavily or Firecrawl are more practical. Gemini supports Google Search natively, with 1,500 free requests per day and $35 per 1,000 after that.
Tools can also be more than simple functions. If you implement personalization as a KnowledgeTriple (subject, predicate, object) memory tool, the LLM generates and stores personalization material in a vector store at each step. Tool design ends up shaping what the agent can do.
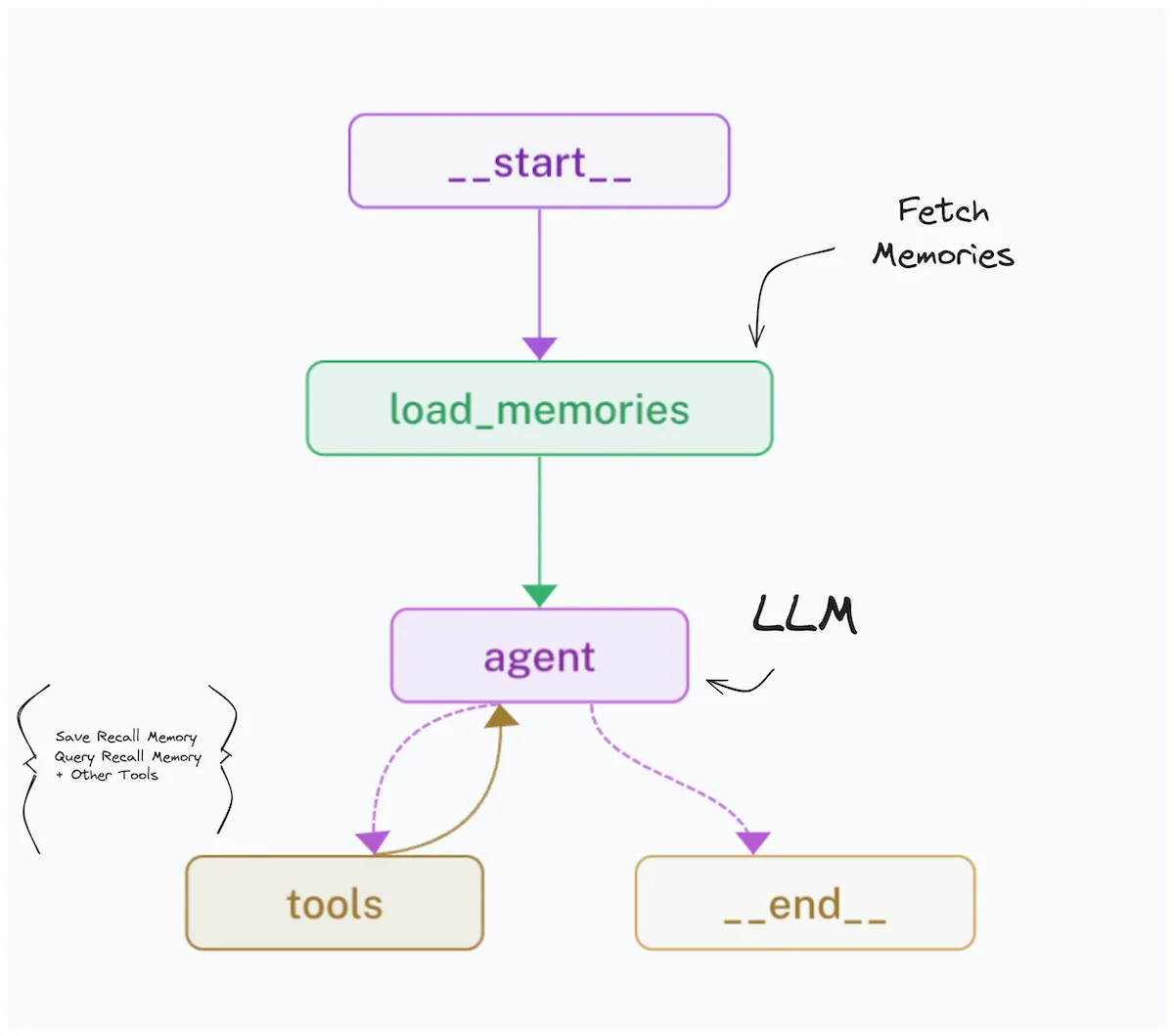
Implementation
Once the tool problem is sorted, the agent itself is relatively straightforward. In Python, zero-base implementation was the fastest path for me. I only used FastAPI, the OpenAI Python SDK, and LiteLLM Proxy. Unify the LLM infrastructure layer around the OpenAI spec and the rest gets simpler. Most backend-focused ML engineers I’ve talked to have their own version of this, though how quickly each company gets there varies.
Take a case where a company model is served via vLLM OpenAI Compatible Server and you need a ReAct agent. LangChain gets you to a prototype fast, and the code compression is real. But the agent behavior spec is locked in, debugging gets harder, and changing library internals is painful. Rolling your own means more boilerplate upfront. The tradeoff is that you can handle changing requirements and use provider-specific features freely. Structured Output is a typical case where self-implementation wins.
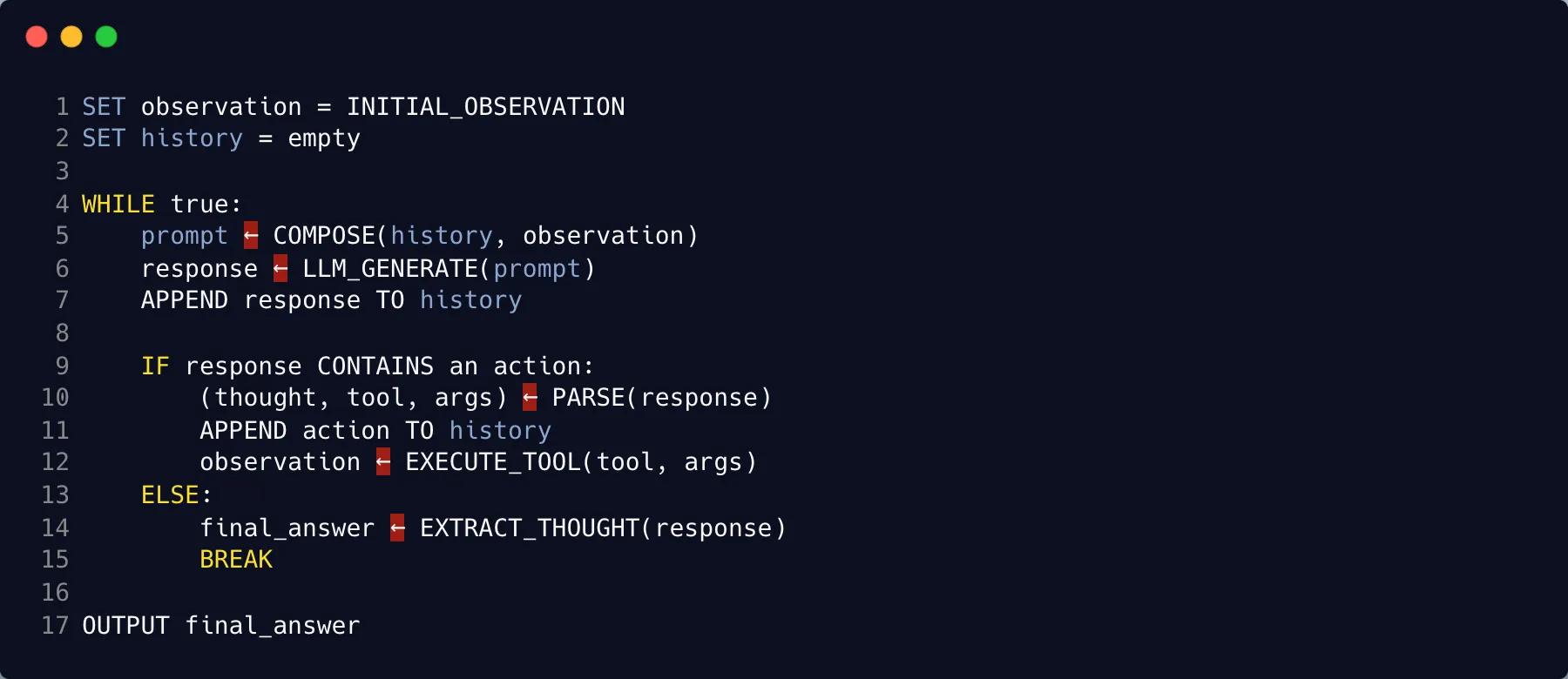
I started from simple pseudo code and had o3-mini turn it into a 134-line Python ReAct agent. Code is on gist.
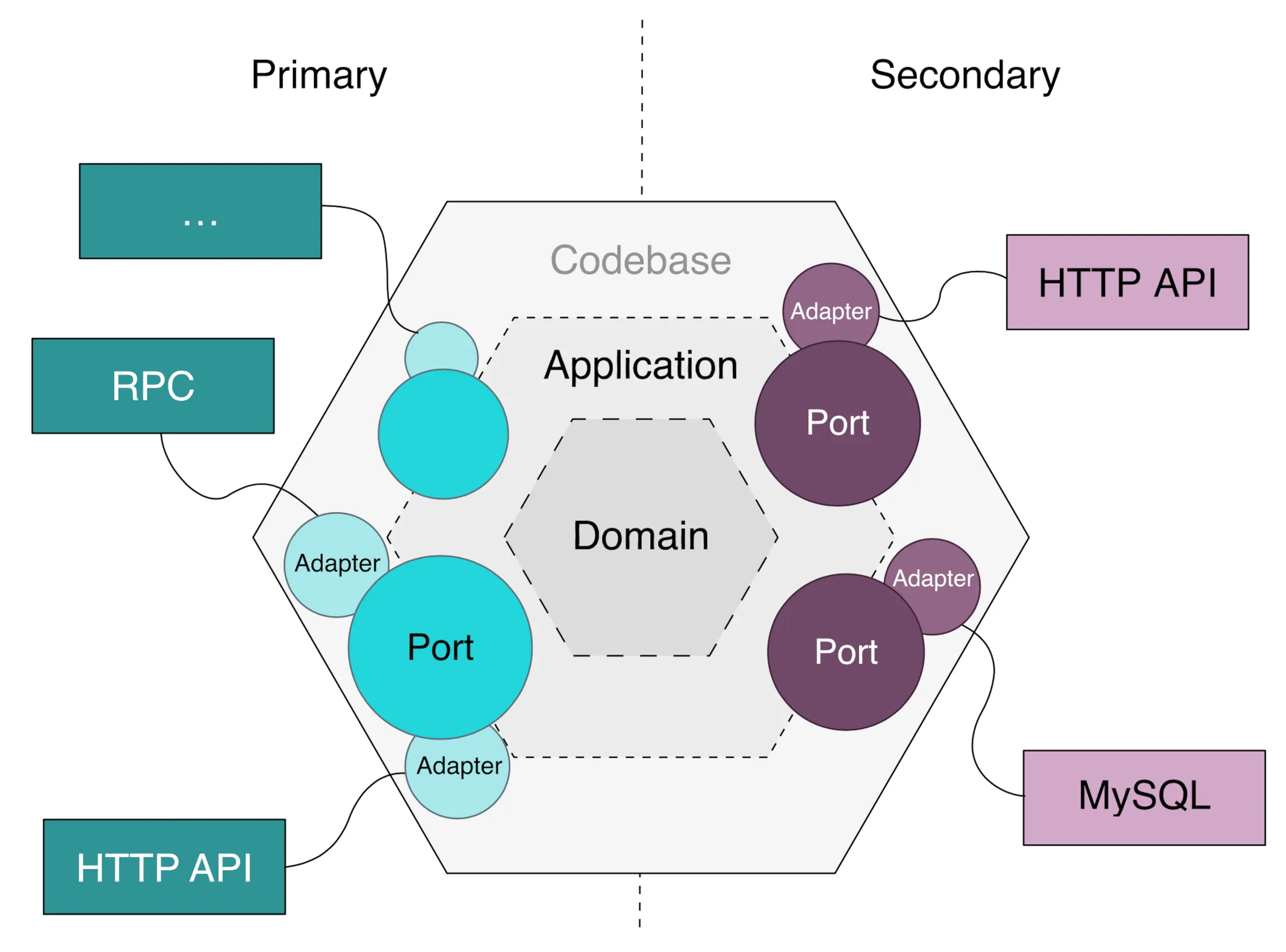
For the LLM layer inside the agent, Port and Adapter works well. Define an abstract LLMProviderService interface, build adapters for each provider (OpenAI, LoraX, etc.), and provider swaps become invisible to the application code. Combine with vLLM OpenAI Compatible Server or LiteLLM Proxy and you’re set.
Evaluation
LLM-as-Judge is the practical path for evaluating agents in conversational systems. MT-Bench’s pairwise comparison, answer grading, and reference-guided grading are solid starting points. WildBench shows you can also evaluate from random conversation logs. The trick is calibrating per-evaluation budget so you can actually afford to run evaluations regularly. Around $5 per round is a reasonable place to start.
Low cost and high quality together means running both end-to-end and per-module evaluations to find the sweet spot. Which model goes in which module, and where the parameters-to-performance ratio makes sense.
This is how I organized the problem. Others will have their own framing.
References
- Huang, W., Abbeel, P., Pathak, D., & Mordatch, I. (2022). Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents. ICML 2022.
- Lu, P., Chen, B., Liu, S., Thapa, R., Boen, J., & Zou, J. (2025). OctoTools: An Agentic Framework with Extensible Tools for Complex Reasoning. arXiv:2502.11271.
- Zheng, L., Chiang, W., Sheng, Y., et al. (2023). Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. NeurIPS 2023.
- Lin, B.Y., Deng, Y., Chandu, K., et al. (2024). WildBench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild. arXiv:2406.04770.
- LINE Engineering. Port and Adapter Architecture.